Designing Data: Proactive Data Collection and Iteration for Machine Learning Using Reflexive Planning, Monitoring, and Density Estimation





Abstract
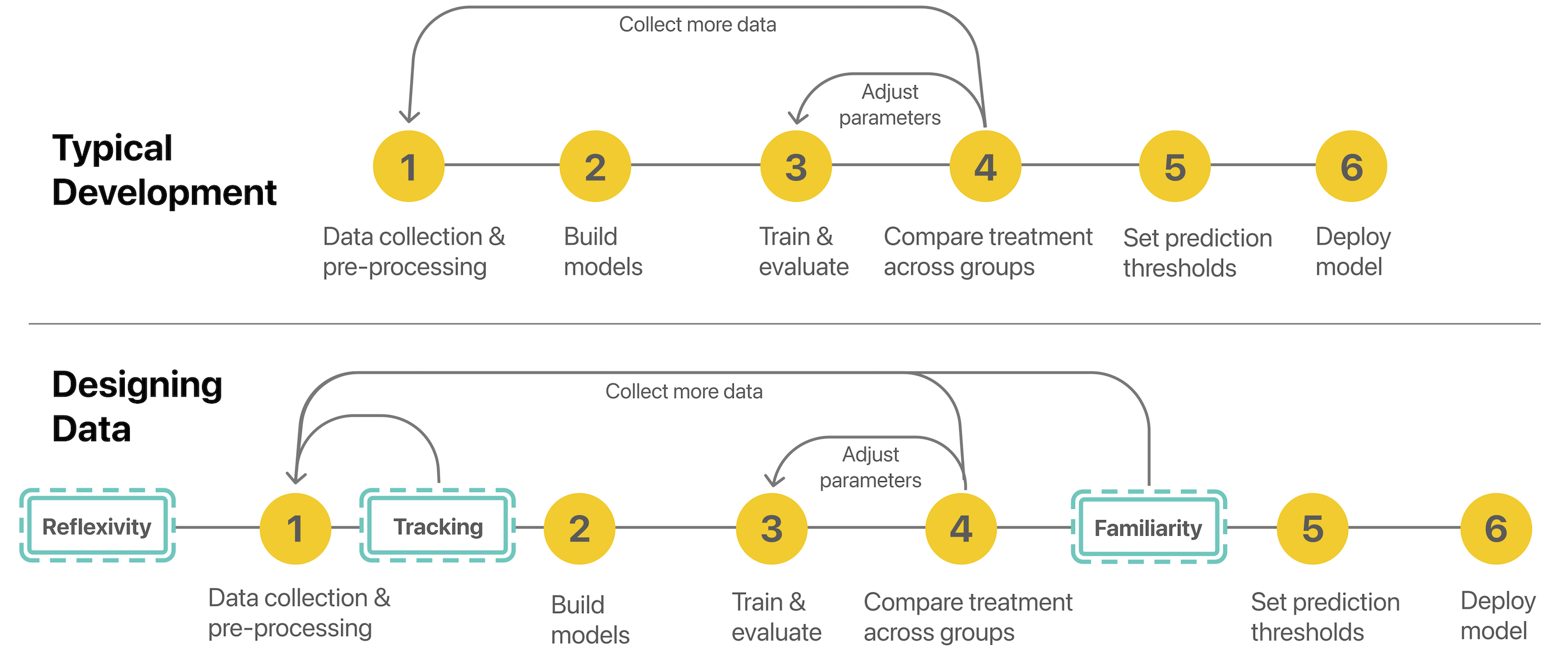
Lack of diversity in data collection has caused significant failures in machine learning (ML) applications. While ML developers perform post-collection interventions, these are time intensive and rarely comprehensive. Thus, new methods to track and manage data collection, iteration, and model training are necessary for evaluating whether datasets reflect real world variability. We present designing data, an iterative, bias mitigating approach to data collection connecting HCI concepts with ML techniques. Our process includes (1) Pre-Collection Planning, to reflexively prompt and document expected data distributions; (2) Collection Monitoring, to systematically encourage sampling diversity; and (3) Data Familiarity, to identify samples that are unfamiliar to a model through Out-of-Distribution (OOD) methods. We instantiate designing data through our own data collection and applied ML case study. We find models trained on “designed” datasets generalize better across intersectional groups than those trained on similarly sized but less targeted datasets, and that data familiarity is effective for debugging datasets.
BibTeX
@article{hopkins2023designing,
title={Designing data: Proactive data collection and iteration for machine learning using reflexive planning, monitoring, and density estimation},
author={Hopkins, Aspen and Hohman, Fred and Zappella, Luca and Cuadros, Xavier Suau and Moritz, Dominik},
journal={Artificial Intelligence & Human-Computer Interaction Workshop at ICML},
year={2023}
}