Understanding and Visualizing Data Iteration in Machine Learning




Abstract
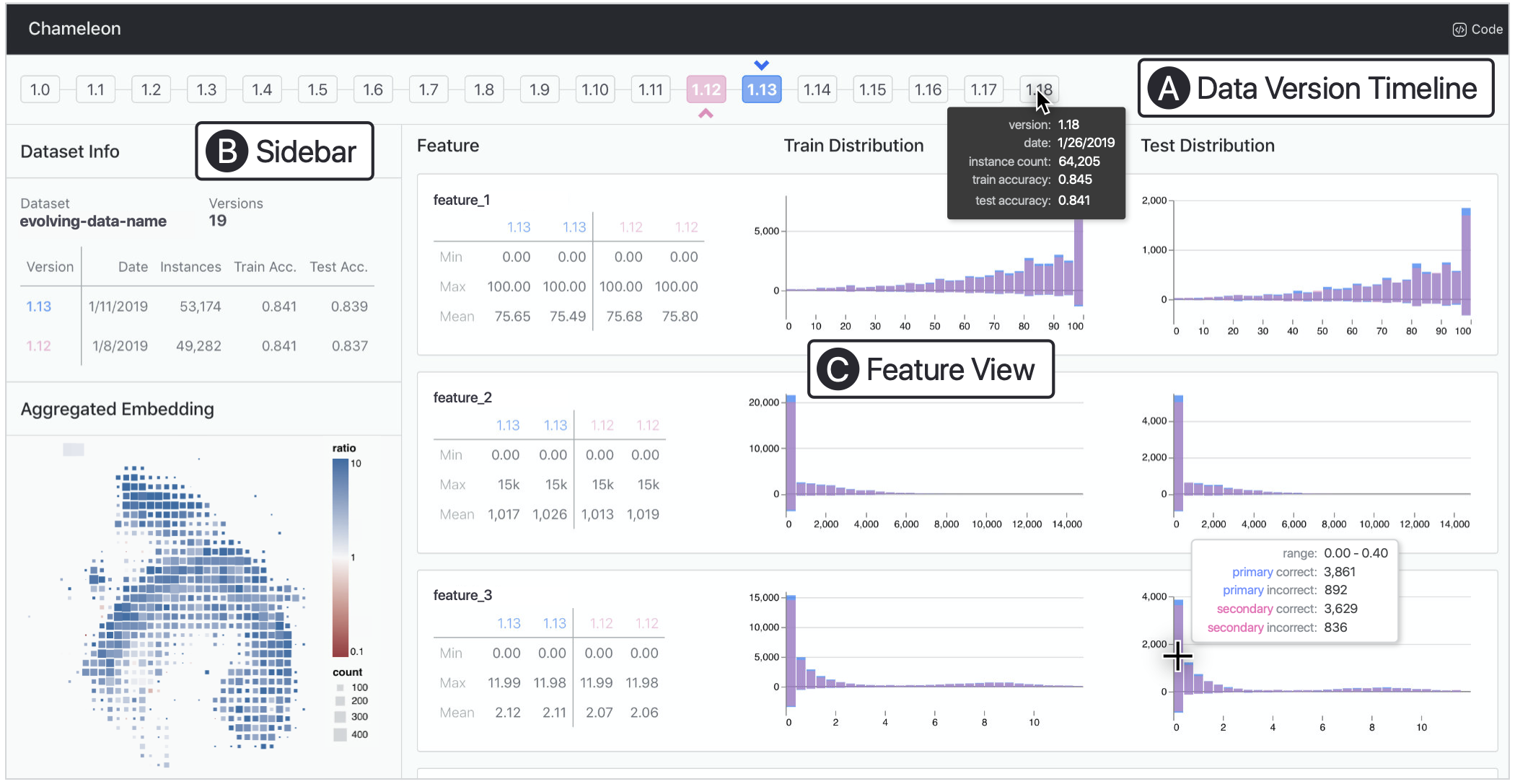
Successful machine learning (ML) applications require iterations on both modeling and the underlying data. While prior visualization tools for ML primarily focus on modeling, our interviews with 23 ML practitioners reveal that they improve model performance frequently by iterating on their data (e.g., collecting new data, adding labels) rather than their models. We also identify common types of data iterations and associated analysis tasks and challenges. To help attribute data iterations to model performance, we design a collection of interactive visualizations and integrate them into a prototype, Chameleon, that lets users compare data features, training/testing splits, and performance across data versions. We present two case studies where developers apply Chameleon to their own evolving datasets on production ML projects. Our interface helps them verify data collection efforts, find failure cases stretching across data versions, capture data processing changes that impacted performance, and identify opportunities for future data iterations.
BibTeX
@inproceedings{hohman2020understanding,
title={Understanding and Visualizing Data Iteration in Machine Learning},
author={Hohman, Fred and Wongsuphasawat, Kanit and Kery, Mary Beth and Patel, Kayur},
booktitle={Proceedings of the SIGCHI Conference on Human Factors in Computing Systems},
year={2020},
organization={ACM},
doi={10.1145/3313831.3376177}
}