What is Summit?
Understanding how neural networks make predictions remains a fundamental challenge. Existing work on interpreting neural network predictions for images often focuses on explaining predictions for single images or neurons, yet predictions are computed from millions of weights optimized over millions of images—such explanations can easily miss a bigger picture.
We present Summit, an interactive visualization that scalably summarizes what features a deep learning model has learned and how those features interact to make predictions.
How does it work?
Summit introduces two new scalable summarization techniques that aggregate activations and neuron-influences to create attribution graphs: a class-specific visualization that simultaneously highlights what features a neural network detects and how they are related.
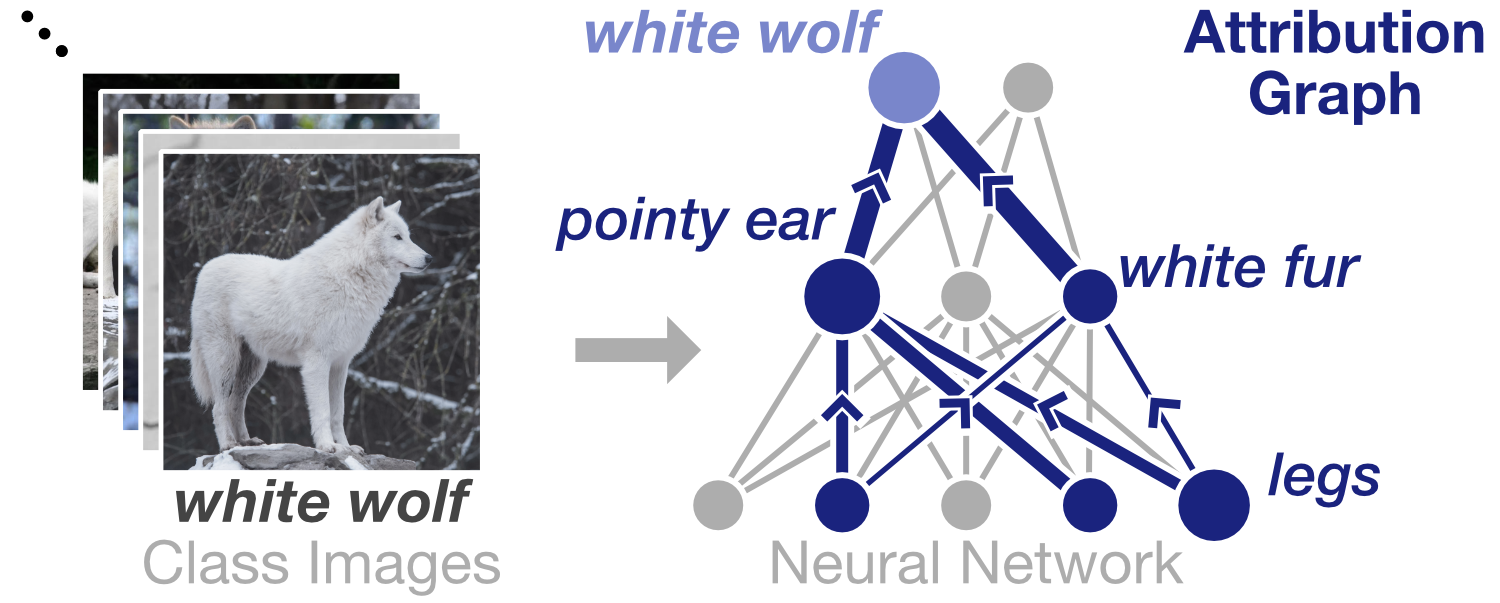
By using a graph representation, we can leverage the abundant research in graph algorithms to extract attribution graphs from a network that show neuron relationships and substructures within the entire neural network that contribute to a model’s outcomes.
Scaling neural network interpretability
Summit scales to large data and leverages neural network feature visualization and dataset examples to help distill large, complex neural network models into compact, interactive visualizations.
Above we demonstrate Summit by visualizing the attributions graphs for each of the 1,000 classes of InceptionV1 trained on ImageNet.
In our paper, we present neural network exploration scenarios where Summit helps us discover multiple surprising insights into InceptionV1's learned representations. Below we describe two such examples.
Example I: Unexpected semantics within a class
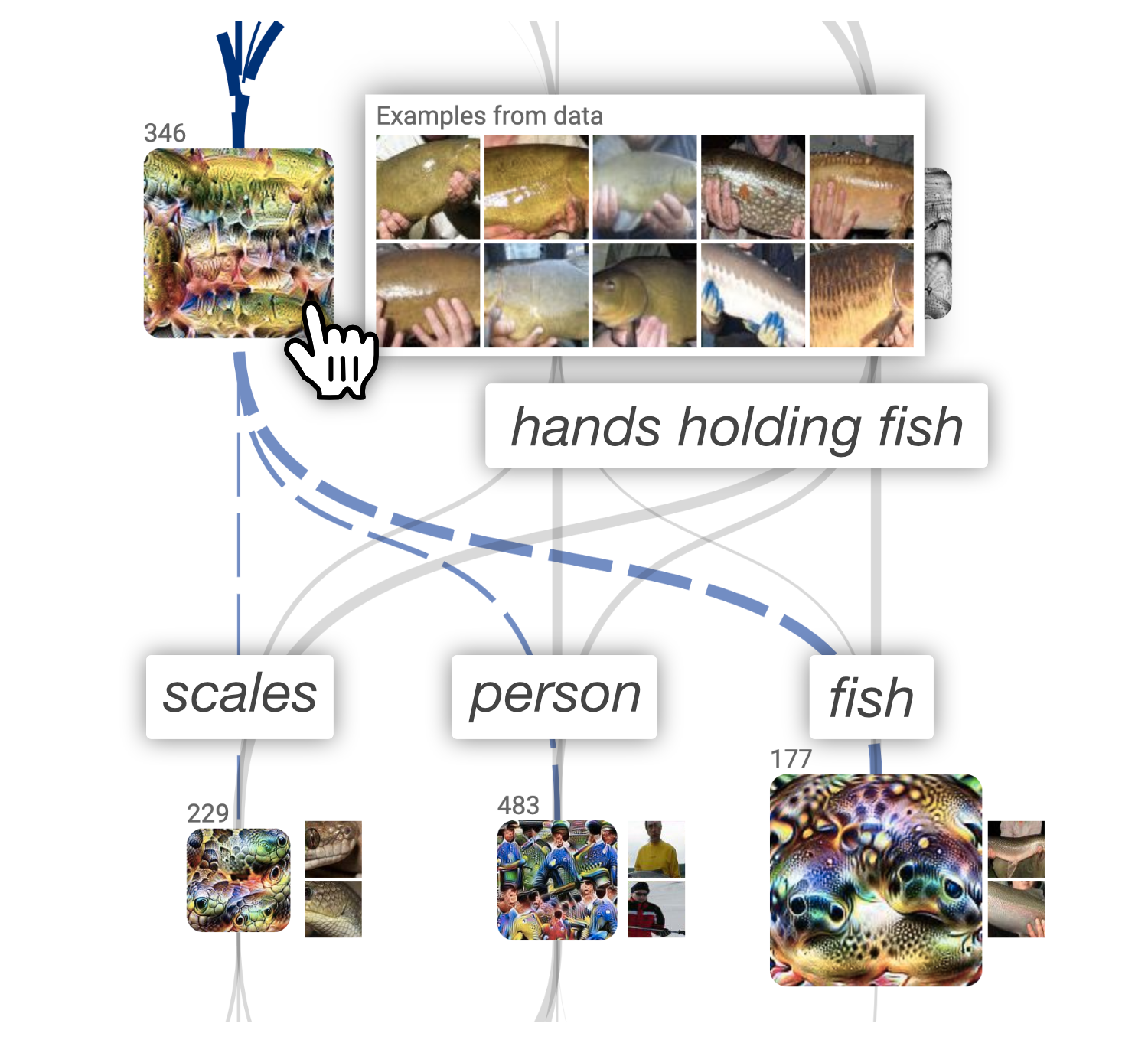
Can model developers be confident that their network has learned what they think it has learned? We can start to answer questions like these with attribution graphs. For example, consider the tench class (a type of yellow-brown fish). Starting from the first layer, we notice the attribution graph for tench does not contain any fish or water features, but instead shows many "finger," "hand," and "people" detectors. It is not until a middle layer, mixed4d, that the first fish and scale detectors are seen; however, even these detectors focus solely on the body of the fish (there is no fish eye, face, or fin detectors).
Inspecting dataset examples reveals many image patches where we see people's fingers holding fish, presumably after catching them. This prompted us to inspect the raw data for the tench class, where indeed, most of the images are of a person holding the fish. We conclude that, unexpectedly, the network uses people detectors and in combination with brown fish body and scale detectors to represent the tench class. Generally, we would not expect "people" as an essential feature for classifying fish.
This surprising finding motivated us to find another class of fish that people do not normally hold to compare against, such as a lionfish (due to their venomous spiky fin rays). Visualizing the lionfish attribution graph confirms our suspicion: there are no people object detectors in its attribution graph. However, we discover yet another unexpected combination of features: while there are few fish-part detectors there are many texture features, e.g., stripes and quills. It is not until the final layers of the network where a highly activated channel appears to detect an orange fish in water, which uses the stripe and quill detectors.
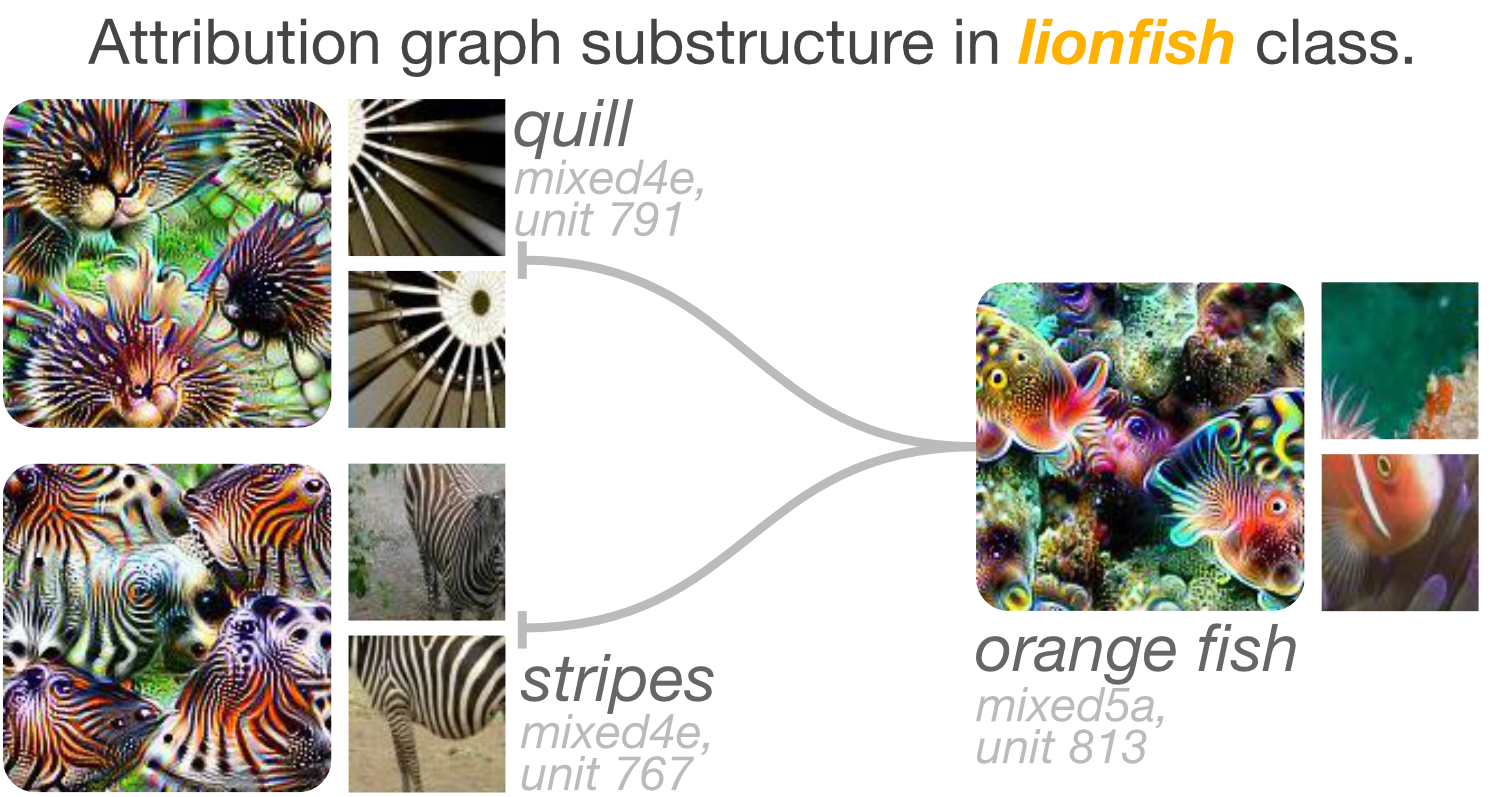
Therefore we deduce that the lionfish class is composed of a striped body in the water with long, thin quills. Whereas the tench had unexpected people features, the lionfish lacked fish features. Regardless, findings such as these can help people more confidently deploy models when they know what composition of features results in a specific prediction.
Example II: Discriminable features in similar classes
Since neural networks are loosely inspired by the human brain, in the broader machine learning literature there is interest to understand if decision rationale in neural networks is similar to that of people. With attribution graphs, we begin to investigate this question by comparing classes throughout layers of a network.
For example, consider the black bear and brown bear classes. A person would likely say that color is the discriminating difference between these animal classes. By taking the intersection of their attribution graphs, we can see what features are shared between the classes, as well as any discriminable features and connections.
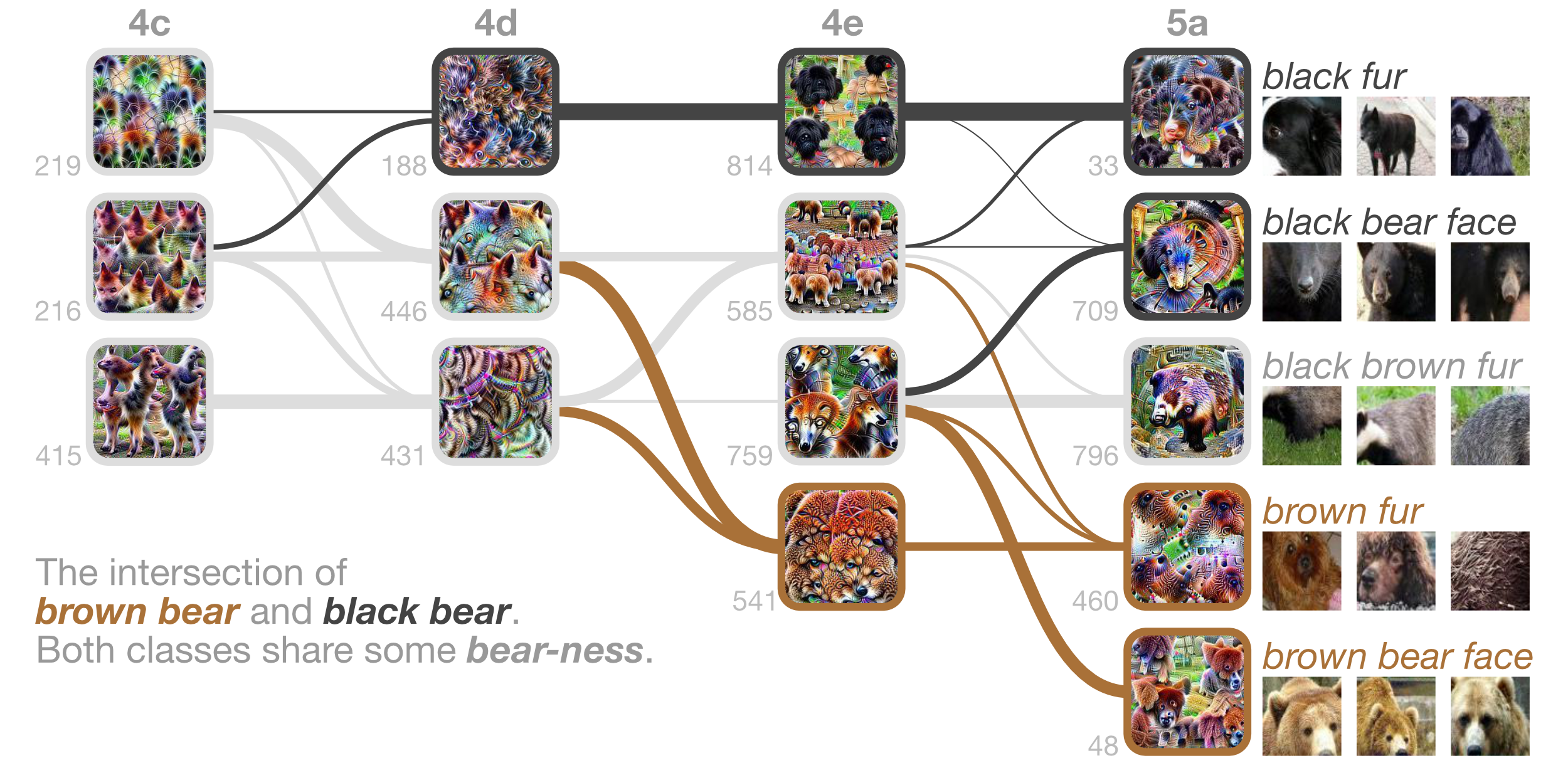
In the figure above, we see in earlier layers (mixed4c) that both black bear and brown bear share many features, but as we move towards the output, we see multiple diverging paths and channels that distinguish features for each class. Ultimately, we see individual black and brown fur and bear face detectors, while some channels represent general bear-ness. Therefore, it appears the network classifies black bear and brown bear based on color, which may be the primary feature humans may classify by. This is only one example, and it is likely that these discriminable features do not always align with what we would expect; however, attribution graphs give us a mechanism to test hypotheses like these.
Summit features
Check out the following video for a quick look at Summit's features.
- Background in deep learning interpretability (0:00 - 0:42)
- Introduction to Summit (0:42 - 1:07)
- Visualizing an attribution graph (1:07 - 2:32)
- Exploring the Embedding View (2:32 - 2:47)
- Scrolling through the Class Sidebar (2:47 - 3:12)
- Searching for and visualizing another attribution graph (3:12 - 3:52)
- Open-source and live demo link (3:51 - 4:08)
Broader impact for visualization in AI
Our work joins a growing body of open-access research that aims to use interactive visualization to explain complex inner workings of modern machine learning techniques. We believe our summarization approach that builds entire class representations is an important step for developing higher-level explanations for neural networks. We hope our work will inspire deeper engagement from both the information visualization and machine learning communities to further develop human-centered tools for artificial intelligence.
Credits
Summit was created by Fred Hohman, Haekyu Park, Caleb Robinson, and Polo Chau at Georgia Tech. We also thank Nilaksh Das and the Georgia Tech Visualization Lab for their support and constructive feedback. This work is supported by a NASA Space Technology Research Fellowship and NSF grants IIS-1563816, CNS-1704701, and TWC-1526254.

Fred Hohman, Haekyu Park, Caleb Robinson, and Duen Horng (Polo) Chau.
IEEE Transactions on Visualization and Computer Graphics (TVCG, Proc. VAST'19). 2020.
- 🏔️ Live demo: fredhohman.com/summit
- 📘 Paper: https://fredhohman.com/papers/19-summit-vast.pdf
- 🎥 Video: https://youtu.be/J4GMLvoH1ZU
- 💻 Code: https://github.com/fredhohman/summit
- 📺 Slides: https://fredhohman.com/slides/19-summit-vast-slides.pdf
- 🎤 Recording: https://vimeo.com/368704428